 Whirl Offload
Whirl Offload
Implementing OpenState with eBPF
This article is a transcription of a talk I gave at FOSDEM 2017 in Brussels, Belgium. The original title was “Stateful packet processing with eBPF: An implementation of OpenState interface”. The abstract, slides and video of the talk should be available here.
Background
Dataplane in Software Defined Networks
The interface for stateful packet processing targets programmable switches in Software Defined Networks (SDN). There is much to say about SDN, but I already wrote an article on the topic. Here we will retain this: such networks include physical or virtual hosts, physical or virtual programmable switches, and controllers that are used to configure the switches in a centralized way.

Packets transit on the networks, being forwarded to their next steps by switches or routers. At the switch level, the dataplane is split between two paths:
-
A “shortcut path” for the packets that require little processing, and that can be directly forwarded by the switch to their next hop.
-
A “standard path1” for packets requiring more processing operations. In this case, the switch is not able to determine the outgoing port itself. So the packet is raised as an “exception”, and sent to the controller. The controller processes the packet and sends it back to the switch, that is expected to be able to handle this new packet.

The “standard path” is used for demanding tasks. Of course, the time induced by sending the packet to and from the controller decreases network performances. Packet encapsulation is an example of task that the switch is often unable to perform by itself. Also, all packets belonging to stateful applications usually go this way.
“Stateful” applications are use cases for which the action to apply to a packet depends on the current state of the flow, that is to say, on the previous traffic of this flow observed by the switch. Port knocking, for instance, is a stateful application. Rate limiting traffic also involve states, since the switch needs to retain how many packets have been processed over the last period of time of a given length.
The idea behind the talk is the following: can we move as many packets as possible from this “standard path” to the “shortcut path” instead? In particular, can we make them smart enough to handle stateful applications, so that they can directly process and forward packets for port knocking or rate limiters, without involving the controller?

The BEBA architecture
Well, if you have read my previous post, you know that this is possible. The partners working on project BEBA have been designing an abstract interface that implements exactly this kind of behavior.
As usual, you can find more information on the project on a previous blog post, or on the official website of the project.
What we call the “BEBA architecture” or, between friends, the “BEBA switch”, encompasses actually tree components.

- OpenState is the interface enabling stateful processing in the switch. We will use it a lot in this article.
- InSP is a model for in-switch packet generation. It is involved in the in-switch ARP processing use case, but we will not use it further in the current post.
- Open Packet Processor (OPP) is the “extended” BEBA interface. It uses the first two components, and also add global and per-flow registers used to evaluate conditions to perform more precise matching. We will come back on this one with the token bucket use case.
OpenState
OpenState was presented in details in a specific post, so here is just the principle. It is an interface used to implement stateful applications, it uses two tables and consists in three steps.

-
The first step is a lookup on the first stable, called “state table”. Matching on flow properties, the lookup return the current state for this flow.
-
The second step consists in a lookup in the second table, the “XFSM table” (for eXtended Finite State Machine, the mathematical model that lies behind). To the flow pattern and its current state, it associates a new state, and an action to perform on the packet).
-
Finally, the state table entry of the flow is updated with the new state retrieved from the XFSM table.
Open Packet Processor
Open Packet Processor (or OPP) has also been the subject of a specific post, but no detailed example had been provided.

In addition to the features provided by the OpenState interface, it defines:
- A set of global registers (think “variables”),
- A set of per-flow registers,
- A set of conditions that can be evaluated based on the values of those registers. The result of this evaluation is used as an additional match pattern for the XFSM table lookup. Also, this lookup returns an additional update function that is used to update both global and per-flow registers (while with OpenState, only the state of the flow was updated).
eBPF
eBPF is an assembly-like language that allows writing userspace program and running it in the Linux kernel. It is based on a former version (BPF or cBPF) and has been under heavy development over the last couple of years. As there are already a lot of resources regarding eBPF, there will not be yet another introduction to the topic on this blog. But if you are looking for documentation, I have a pretty good list of readings about eBPF here.
In the example use cases we consider here, we work with eBPF tc hook, meaning that the program will be:
- Compiled with clang/LLVM from C,
- Injected into the kernel with tc (Linux tool for traffic control), that
relies on the
bpf()syscall to do that, and sent to thecls_bpfclassifier - Checked by the kernel verifier, to ensure that it is safe and secure and will not crash the kernel or leak memory,
- Possibly Just-In-Time (JIT)-compiled,
- And then attached to the traffic control interface.

Then the program will be run for each packet received on its tc interface (ingress or egress, depending on when the user chose to attach it; ingress in our examples).
Stateful processing
Maps provides states
So, the eBPF program runs on a packet. Once it finishes, its state is discarded, the contents of all the eBPF registers is lost, and the next packet will start a new execution from scratch. eBPF has no state by default.
Happily, eBPF has a feature called maps (or sometimes tables): it can read and write from/to a specific memory area. These maps are persistent across distinct runs of a program, so they bring states!
More specifically, they can be used to:
- share data between several executions of a same eBPF program,
- share data between different eBPF programs, or
- share data between one or more eBPF programs and userspace programs.
Here we have no interest in the second item. The first item of the list, data
sharing between program instances, brings states, and we need it of course; the
third item, access to the map from userspace through the bpf() system call,
provides a handy way to initialize the maps before we start running a stateful
eBPF application.
Among the several kind of maps provided by the kernel (array with integer indices, longest-prefix match, other eBPF programs storage, maps specific to some other features…), we have hashmaps that can be used to store any kind of generic data as keys and values. We can use it for the two tables of the BEBA interface.
So let’s sum up. We have this eBPF in-kernel facility that provides stateful packet processing, thanks to maps. We have the BEBA interface that can be used to efficiently model stateful applications. We can combine the two and see how we can provide an implementation of this interface, with eBPF. To illustrate this, here are two example applications: in-switch port knocking, and a rate-limiter token bucket.
First case study: port knocking
Remember we already used port knocking as an example use case for OpenState? As a reminder, here is the basic principle: the server wants to “hide” a port, say TCP 22 for SSH, to other hosts, and only opens it if it receives a secret sequence of packets: for example, UDP packets on ports 1111, 2222, 3333 and 4444, in this order.

Here we implement port knocking at the switch level, meaning that the switch itself is to allow or to drop packets for TCP port 22 of the server, depending on whether it has “seen” the correct sequence before.
So we unroll the OpenState phases: the first step is the state table lookup. The switch searches the table for the first entry corresponding to the flow the packet belongs to, and returns the current state for this flow.

Initially, the state table for port knocking is nearly empty. It only contains a default rule returning the initial state for all flows.
| Flow matching pattern | State |
|---|---|
| … | … |
| IP src = any | DEFAULT |
So the flow is in initial state, the secret sequence has not been observed yet. Now the switch moves to the second phase, the XFSM table lookup. It matches on an “event” and on the current state.

In our case, the event can be translated by “is that packet the first one of the secret sequence?” if so, both event and state in the first entry depicted below match, and we obtain a new state (STEP_1) and an action (Drop) to apply to the packet. Otherwise, the last rule of the table applies and packet is dropped all the same, but we remain in the initial state.
| Flow matching pattern | Actions | ||
|---|---|---|---|
| State | Event | Action | Next state |
| … | … | … | … |
| DEFAULT | UDP dst port = 1111 | Drop | STEP_1 |
| STEP_1 | UDP dst port = 2222 | Drop | STEP_2 |
| STEP_2 | UDP dst port = 3333 | Drop | STEP_3 |
| STEP_3 | UDP dst port = 4444 | Drop | OPEN |
| OPEN | TCP dst port = 22 | Forward | OPEN |
| OPEN | Port = * | Drop | OPEN |
| … | … | … | … |
| * | Port = * | Drop | DEFAULT |
In both cases, the switch now has to update the state table with the new state for this flow (even if, in the second case, there was no state change).

The table below is the result of the packet successfully validating the first part of the secret sequence: in the state table, the flow now appears in state STEP_1.
| Flow matching pattern | State |
|---|---|
| … | … |
| IP src = 10.3.3.3, IP dst = 10.1.1.1 | STEP_1 |
| … | … |
| IP src = any | DEFAULT |
Next packet for this flow, providing it matches the correct event in the XFSM table, is susceptible to make the state progress from another step, until the state OPEN is reached, thus allowing the switch to forward packets to TCP port 22.
Now at last, here is the eBPF code! It is written in C, and has to be compiled into eBPF bytecode. I only provide the interesting samples here, the full code is available on GitHub (see References at the bottom of this page).
This first snippet is from the header file I use, openstate.h, and describes
the two tables for the interface:
/* State table */
struct StateTableKey {
uint16_t ether_type;
uint32_t ip_src;
uint32_t ip_dst;
};
struct StateTableVal {
int32_t state;
};
/* XFSM table */
struct XFSMTableKey {
int32_t state;
uint8_t l4_proto;
uint16_t src_port;
uint16_t dst_port;
};
struct XFSMTableVal {
int32_t action;
int32_t next_state;
};
We match flows in the state table depending on the ethertype field of the packet (which identifies the protocol used on layer 3, IPv4 in our case), on IPv4 source and destination addresses. The lookup will return a integer representing the state. This is pretty straightforward. In a similar way, we describe the fields in use for state and event matching in the XFSM table, and the returned structure has an action and state as integers.
Now file portknocking.c implements the logics of the application. It
describes the state table lookup as follows:
/* [Truncated]
* Parse headers and make sure we have an IP packet, extract src and dst
* addresses; since we will need it at next step, also extract UDP src and dst
* ports.
*/
state_idx.ether_type = ntohs(ethernet->type);
struct StateTableKey state_idx;
state_idx.ip_src = ntohl(ip->src);
state_idx.ip_dst = ntohl(ip->dst);
/* State table lookup */
struct StateTableVal *state_val = map_lookup_elem(&state_table, &state_idx);
if (state_val) {
current_state = state_val->state;
/* If we found a state, go on and search XFSM table for this state and
* for current event.
*/
goto xfsmlookup;
}
goto end_of_program;
If we successfully obtained a state from this first lookup, we move to XFSM lookup, and then state table update and packet processing with the new state and action we retrieved from the lookup. This occurs in the same file.
/* Set up the key */
xfsm_idx.state = current_state;
xfsm_idx.l4_proto = ip->next_protocol;
xfsm_idx.src_port = 0;
xfsm_idx.dst_port = dst_port;
/* Lookup */
struct XFSMTableVal *xfsm_val = map_lookup_elem(&xfsm_table, &xfsm_idx);
if (xfsm_val) {
/* Update state table entry with new state value */
struct StateTableVal new_state = { xfsm_val->next_state };
map_update_elem(&state_table, &state_idx, &new_state, BPF_ANY);
/* Return action code */
switch (xfsm_val->action) {
case ACTION_DROP:
return TC_ACT_SHOT;
case ACTION_FORWARD:
return TC_ACT_OK;
default:
return TC_ACT_UNSPEC;
}
}
That’s it! Well we skipped the header parsing part, but you can find it in the
complete example on GitHub, or other examples such as in the Linux kernel
sources under linux/samples/bpf/. Now we have the C program, we can compile
it to eBPF bytecode with:
$ clang -O2 -emit-llvm -c portknocking.c -o - | \
llc -march=bpf -filetype=obj -o portknocking.o
This produces an ELF object file. The tc tool for traffic control on Linux, for
example, is able to extract the bytecode from this object file, and to inject
it into the kernel by calling the bpf() syscall. On the user side, the
commands looks like:
# tc qdisc add dev eth0 clsact
# tc filter add dev eth0 ingress bpf da obj portknocking.o
Oh wait, there is one more thing we have to do before running the program: we
have not initialized the maps! We can do this with a user-space program that,
again, uses the bpf() syscall to read into the maps pinned under
/sys/fs/bpf/tc/ by tc.
Alternatively, all those steps (compiling, injection, initialization) could be performed in a simpler way by using the Python wrappers (that call into a C library) available from the bcc framework. See the tutorials related to this project to learn how to do so (If you want to play with eBPF, these tools totally deserve a moment of your time, and will probably make handling programs easier).
Here is a screenshot of the port knocking application running. It has nothing impressive, really. On the first terminal (top left) I send TCP packets from client to host on TCP port 22, then the secret sequence, then again packets on TCP port 22. On the terminal on the server machine, we can observe that only TCP packets on port 22 sent after the secret sequence are received. The terminal on the bottom was opened on the machine acting as a switch (or in this case, more like a router), and displays the commands I used to compile the program, to attach it to the tc ingress interface, and to initialize the maps.
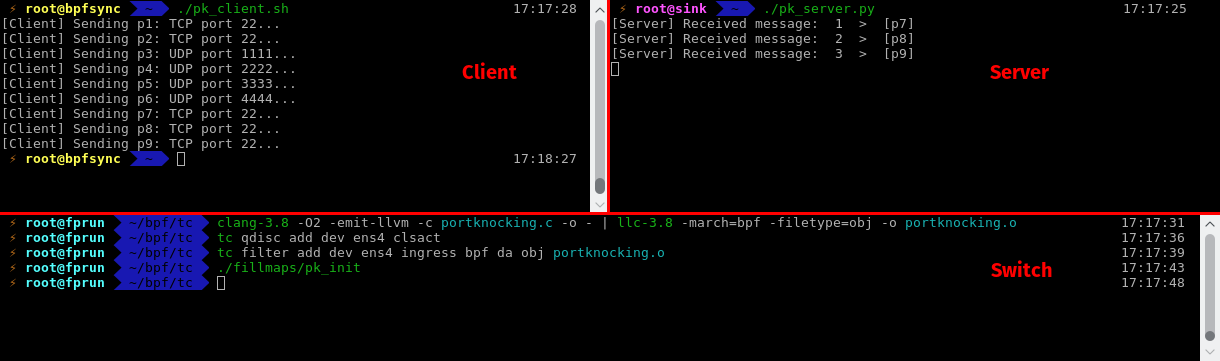
(Click to view full size)
Second case study: token bucket
Port knocking is a nice example to explain how stateful applications work, but it hardly justifies by itself the creation of an abstract interface for stateful packet processing: it is not something really used in the industry.
Instead, we focus in this section on another use case for the BEBA interface: a rate limiter based on a token bucket. This is a useful one, and in addition, it also illustrates the advantages of Open Packet Processor, the “extended” version of the BEBA interface.
Here again, the concept is simple: we have a virtual bucket with a given maximal capacity, and it contains token. Tokens are generated at a regular rate, and one is consumed each time a packet is forwarded. So if too many packets arrive in the same time interval, all tokens are consumed and some packets have to be dropped, thus limiting the rate of the traffic.
Because of the way the BEBA interface is designed, we cannot implement the bucket in the naive way, with a counter for the number of tokens. This is because with such a vision of the algorithm, each time a packet is processed, we would have first to update the number of tokens in the bucket, then check that there are enough tokens, and finally decrement the counter if a packet has been forwarded. This is not possible in our case: there is only one update step, and it occurs at the end of the cycle (making the bucket level impossible to update and to reflect the number of tokens available at packet arrival time).
Instead, we rely on an alternative algorithm, with a sliding window. Time is split into intervals of a given length, and the window spans on as many intervals as the number of tokens the bucket can contains. Then depending on when a packet arrives, three cases can occur:
-
In case of normal traffic, the packet arrives between the bounds of the time window. It is forwarded, and the window is shifted on a distance corresponding to one interval to the “right”, hereby representing the consumption of a token.
-
In case of light traffic, the window has not been moved in a while, and the packet arrives “before” (on the right of) the window: the packet is forwarded, and the position of the window is reinitialised on the position of the current packet.
-
In case of heavy traffic, the window has been moved a lot to the right, and the packet arrives “after” its boundaries (on the left of the window): there is no token left for this packet, it is dropped. The window position is unchanged, and remains at its current place until time reaches its boundaries and packets arrive within the window limits again.

Our example implements one bucket per IP source address.
So why do we need the extended interface here? We have to store the current values for the bounds of the window, Tmin and Tmax. And we can use per-flow registers for that. These registers are stored in the state table. Based on the value we retrieve from the lookup, we define two conditions:
cond1 = (t ≥ Tmin)cond2 = (t ≤ Tmax)
This conditions can be evaluated before the XFSM lookup, and the results determines the case the current packet falls in:
cond1 == true && cond2 == true→ Case 1 (packet arrived within windows boundaries)cond1 == true && cond2 == false→ Case 2 (packet arrived “on the right side“)cond1 == false→ Case 3 (packet arrived “on the left side”)
From these conditions we can determine in which case we are, and match in the XFSM table accordingly (in the “event” column). In this use case, the state value itself is of little interest, and the actual evolution of the traffic is instead stored into those per-flow registers (that also store states, even if they do not wear the name).
On the eBPF side, we need just a couple of additional components in regard to
the previous case study. First, we need something to get the arrival time of
the packet. This is trivial: Linux provides a kernel helper for this
(ktime_get_ns()), a function that can be called directly from within the eBPF
program, and that returns the current time (since boot) in nanoseconds.
We also need to somehow encode the conditions in the program, as well as the
results of their evaluation that will be stored in the key structure of the
XFSM table. Not hard to do with an enumeration of the possible outcomes. For
the two table lookups, for example, the code in tokenbucket.c becomes:
uint64_t tnow = ktime_get_ns();
/* State table lookup */
state_val = map_lookup_elem(&state_table, &state_idx);
current_state = state_val->state;
tmin = state_val->r1;
tmax = state_val->r2;
/* Evaluate conditions */
int32_t cond1 = check_condition(GE, tnow, tmin);
int32_t cond2 = check_condition(LE, tnow, tmax);
if (cond1 == ERROR || cond2 == ERROR)
goto error;
/* XFSM table lookup */
xfsm_idx.state = current_state;
xfsm_idx.cond1 = cond1;
xfsm_idx.cond2 = cond2;
xfsm_val = map_lookup_elem(&xfsm_table, &xfsm_idx);
The tables themselves do not change much, they only receive additional fields for the per-flow registers and the results of condition evaluation.
Regarding global registers, that are also part of Open Packet Processor, we are supposed to put them in a third table. But in the current use case, they are used only for the bucket capacity and regeneration rate, that are constants. So instead we just use constants in the eBPF program, hence gaining in speed. A third time would be easy to create, on the model of the other two ones, for an application that would need to update the global values as part of the update function returned from the XFSM lookup.
The program can be compiled and injected into the kernel in a way similar to the port knocking application. Again, here is a screenshot!
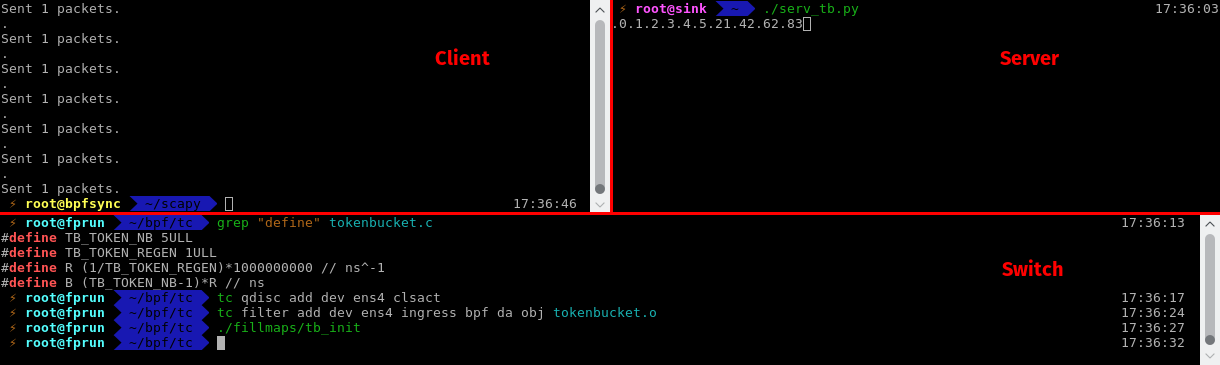
(Click to view full size)
We observe packets sent with scapy (100 packets) on the terminal from the host (top left). On the lower terminal, on the switch, the application is compiled and attached to tc ingress interface. The bucket has a maximum capacity of 5 tokens, and generates one token every second. Initially, the bucket is full. On the server (top right), we observe that the first 6 tokens are forwarded (one token has been generated before the first 5 were consumed), then most packets are dropped. Only 1 packet every 20 or so is forwarded. It works, hooray!
Conclusion
Limits
eBPF in Linux is still under heavy development, and some additional features may appear in the future. Meanwhile, some of the most important limitations of this implementation of the BEBA interface are:
-
The absence of a wildcarding mechanism for map lookup. This makes it impossible (or at least, hard) to implement something like “please match UDP packets on any port number”. Some people have expressed interest for such a feature with the maps, so who knows, maybe it will appear someday.
-
Also, we may have issues with concurrent accesses to maps if the program is to be run on a multiprocessor machine. Update on the hashmaps are protected by the RCU mechanism, but this does not prevent programs to mess up with states if some program updates the map between the lookup and update steps of another instance. One solution is to use per-CPU hashmaps, a possibility offered by the kernel. It can be suitable for a number of applications, not for all of them.
Next steps
Some leads for future work:
-
The whole idea of the BEBA interface is not only to provide a model for stateful applications, but also a kind of language that would directly implement the program. In other words: a high-level language that could be used to easily describe token bucket and to actually generate the C code of the eBPF program, without the user having to touch the C code at all. This is what happens with the reference BEBA implementation, on top of Ryu (for the controller) and ofsoftswitch (for the dataplane), but we do not have it for the eBPF implementation at this time.
-
On the technical side, I have been using tc to attach programs to the tc interface so far, and I would really like to try the XDP hook instead to see what performance could be obtained for this solution.
Questions
The only question I got at the end of the talk was about performance (well, I was waiting for it). I had no performance results at that time, so I made an answer based on the ones from Brenden Blanco: single drop with tc on a single processor at 3.7 GHz can deal with 4.2 Mpps. XDP for single drop was, at that time, around 20 Mpps (expect hight now), and forwarding back on the same port was at 10 Mpps.
As of this writing, I could realize some tests of my own. I have a different machine with a 2.3 GHz CPU. The figures I have got on one core, for 64-byte long packets, are:
- 1.00 Mpps with no eBPF program attached.
- 0.97 Mpps with a simple eBPF program that only returns
TC_ACT_OK. - 0.81 Mpps with the eBPF token bucket attached2.
- 0.20 Mpps for a normal token bucket with a token generation rate of 200,000 tokens per second… which shows that the application works! (By the way, the precision is great: I measured values comprised between 199,999 and 200,002 pps.)
I have not tried with XDP for now, though. Of course, it is normal we have expect lower performances with a token bucket attached, since:
- We perform some advanced processing of the packets.
- We use hashmaps. With hashes! Three hashes per packet, they do add a lot of cycles.
Other questions I had later in the day were related to the other use cases for BEBA (but you, my loyal reader, already have some idea about what they are, right?), or with the possibility to interact with P4. I know that there is a backend to produce eBPF code from P4, but apparently some people seem to be interested in producing P4 code from eBPF as well, in order to program ASICs. I do not know whether this is possible, but that sure sounds like an intriguing question.
References
- The page of this talk, on FOSDEM’17 website.
- The full code for the port knocking example, on GitHub.
- The full code for the token bucket example, on GitHub.
- BEBA project GitHub repository, with reference implementation of the interface for the controller (beba-ctrl, based on Ryu) and the programmable switch (beba-switch, based on ofsoftswitch).
- The habitual list of BEBA public deliverables, to get every details about the project, the interface, the use cases.
-
The “shortcut path” and the “standard path” mentioned in this article are usually referred to as “fast path” and “slow path”. But the latter terms also have a particular connotation when associated to 6WIND’s products (or even sometimes other commercial products). Since the “paths” here have nothing to do with the technology specific to the company, I picked different terms to avoid confusion. ↩
-
The token bucket has been modified in order to let all packets pass. The processing of packets and the implementation of the BEBA interface is performed the same way a normal token bucket would do, except that in the end, all packets are forwarded, regardless of the action retrieved from the XFSM table, so that we can measure throughput. ↩